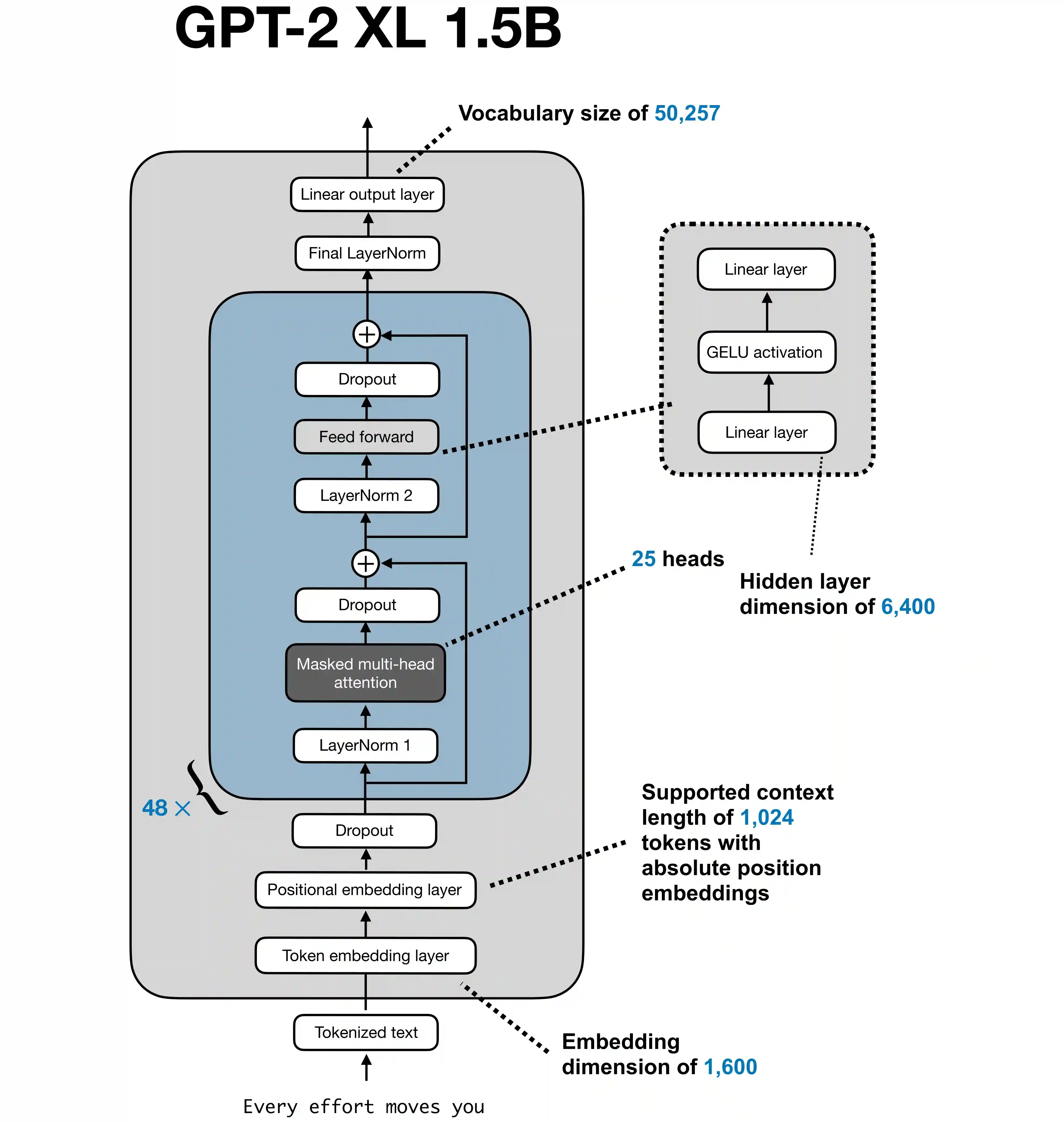
LoRA Fine-Tuning Explained: What It Is, Why It Works, and the Math Behind It
LoRA stands for Low-Rank Adaptation. It is one of the most useful ideas in modern LLM fine-tuning because it changes the question from: How do we update all of the model's weights? to: How do we learn a small update that is still expressive enough for the new task? That is the whole trick. Instead of fine-tuning every entry of a large weight matrix, LoRA keeps the original pretrained weight frozen and learns a low-rank correction on top of it. This makes training much cheaper in parameters, optimizer state, checkpoint size, and often VRAM. ...