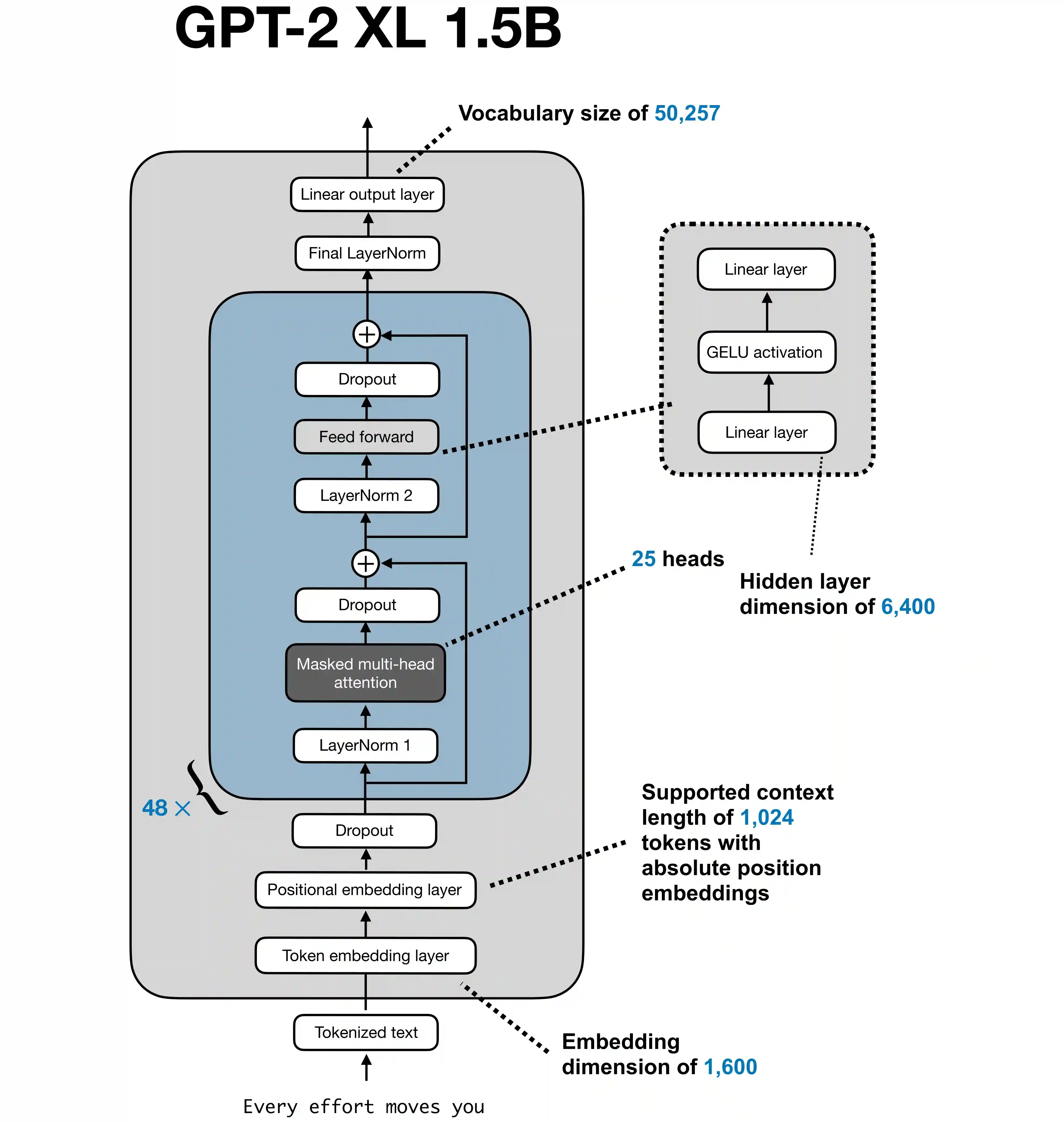
Training Loop Explained: Batches, Epochs, Iterations, and Convergence
Once you understand neurons, activations, loss functions, and backpropagation, the next thing to understand is the training loop. This is the repetitive engine of deep learning. At a high level, training is boring in the best possible way. It is the same four steps repeated over and over: make a prediction measure the error compute gradients update the weights The interesting part is not the loop itself. The interesting part is how concepts like batch size, epoch, iteration, and convergence affect the behavior of that loop in practice. ...