Large language models (LLMs) like GPT-4, Llama, or Grok generate text by running inference — the phase where a trained model produces outputs from a given input prompt. While training is resource-intensive and done once, inference happens every time a user sends a query. Understanding the mechanics of inference is key to grasping why some models feel “fast” while others lag, and why certain optimizations matter.
At a high level, modern LLM inference (for autoregressive transformer-based models) splits into two distinct phases: prefill and decode. These phases behave very differently in terms of computation and directly affect two critical user-facing metrics: Time to First Token (TTFT) and Inter-Token Latency (ITL).
The Two Phases of Inference
1. Prefill (Prompt Processing)
When you send a prompt to an LLM, the model first processes the entire input sequence all at once. This is called the prefill phase.
- The transformer processes every token in the prompt in parallel.
- For each layer, it computes attention over the full prompt and generates the key-value (KV) cache — a stored representation of the prompt’s keys and values that will be reused later.
- No new tokens are generated yet; the model is just building the internal state needed for generation.
2. Decode (Token Generation)
After prefill, the model starts generating output tokens one by one. This is the decode phase, and it is inherently sequential (autoregressive).
- The model predicts the next token.
- That token is appended to the sequence.
- The new key and value for this token are computed and added to the KV cache.
- Attention is recomputed using the cached KV states from all previous tokens (prompt + generated so far) plus the newly computed ones.
- Repeat until the desired length or stop condition.
Because each new token depends on all previous ones, decoding cannot be parallelized across output tokens — you must generate them sequentially. This makes decode much slower per token than prefill.
The KV cache is crucial here: without it, every decode step would require re-computing attention over the entire growing sequence from scratch (O(n²) cost). With the cache, each decode step only needs to compute new keys/values and attend to the cached past, keeping cost roughly O(n) total across the whole generation.
Key Performance Metrics
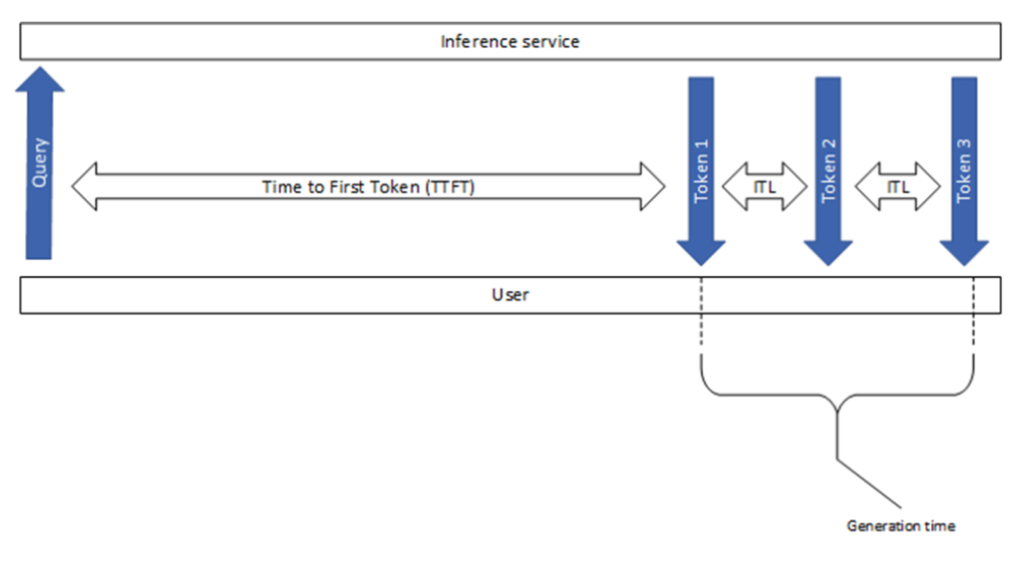
Time to First Token (TTFT)
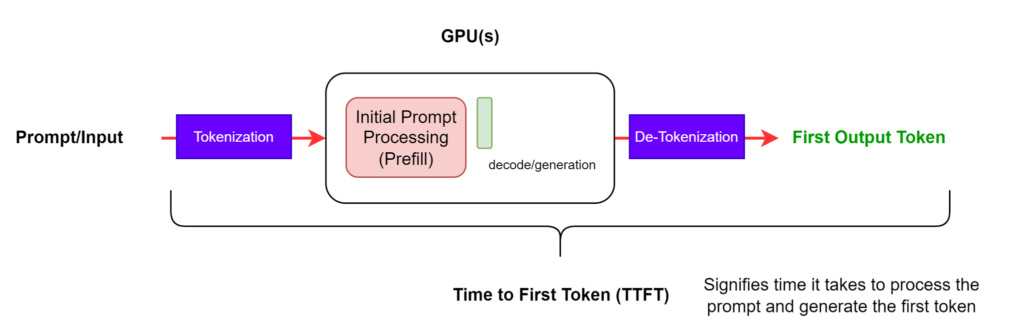
TTFT measures the delay from when the request is submitted until the very first output token appears in the response stream.
- TTFT ≈ prefill time + time to compute the first decode step.
- Long prompts → higher TTFT (because prefill processes everything upfront).
- TTFT is critical for perceived responsiveness. Users notice if the model “hangs” before starting to reply.
Inter-Token Latency (ITL)
ITL (sometimes called Time Per Output Token or TPOT) is the average time between consecutive output tokens once generation has started.
- ITL is dominated by the decode phase.
- Lower ITL means the text streams in faster and feels snappier.
- Typical values on high-end hardware for large models range from 20–100 ms per token, translating to 10–50 tokens per second.
Together, TTFT and ITL define the end-user experience:
- Low TTFT → quick start.
- Low ITL → fast streaming completion.
Why the Split Matters in Practice
The prefill/decode split creates an asymmetry:
- Short prompts + long outputs → TTFT is low, but total time is dominated by slow sequential decoding.
- Long prompts + short outputs → TTFT can be high (prefill is expensive), but once it starts, completion is quick.
This is why techniques like:
- Batching multiple user requests together,
- KV cache quantization,
- Speculative decoding (guess several tokens ahead and verify),
- Paged attention or vLLM-style memory management,
are so important — they primarily accelerate the decode phase or make prefill more efficient under load.
Prefill is compute-bound (FLOPs-bound). The dominant operations are large matrix multiplications (Q @ Kᵀ and attention @ V) over the full prompt length. These require a massive number of arithmetic operations—far more computation than data movement. Modern GPUs excel in this regime because they are designed for high-throughput floating-point operations when given large, parallel workloads. The phase is “embarrassingly parallel,” so the hardware can operate near peak FLOPs utilization.
Decode, in contrast, is memory-bound. Each decode step generates only one token, so the matrix multiplications are tiny (shape [1 × d] against the cached KV of length n). There is relatively little arithmetic to do, but the model must load the entire KV cache (which grows with every token) from GPU memory into the compute units. The bottleneck shifts from computation to memory bandwidth: moving large amounts of data with minimal work per byte.
This compute-vs-memory distinction has major implications for real-world inference systems, especially when serving multiple users concurrently.
Inference engines like vLLM exploit this insight in their scheduling:
- They maintain two queues: a waiting queue (new requests needing prefill) and a running queue (ongoing generations in decode).
- The scheduler prioritizes the running (decode) queue over the waiting (prefill) queue. This prevents long, compute-heavy prefills from starving latency-sensitive decode steps, which would otherwise cause visible stuttering in streaming responses.
- Chunked prefill (also called iterative or incremental prefill) further improves fairness: instead of processing an entire long prompt in one massive batch slot, vLLM breaks it into smaller chunks. This caps the amount of compute a single prefill can consume in one iteration, allowing decode steps from other requests to interleave and progress without long delays.
These techniques help maintain low ITL and predictable latency even under mixed workloads with varying prompt lengths. Understanding the bound differences explains why simply throwing more GPUs at inference doesn’t always yield proportional speedups—decode-heavy workloads are often limited by memory bandwidth rather than raw compute power.
Summary
LLM inference is not a single uniform process. The prefill phase parallel-processes the prompt to build the KV cache, while the decode phase sequentially generates tokens using that cache. TTFT captures how long you wait for the response to start (mostly prefill), and ITL measures how fast the rest streams in (pure decode).
Understanding these basics explains many real-world behaviors: why long context hurts responsiveness, why streaming feels better than waiting for full output, and why inference optimization is an active and crucial research area.
Next time you notice a model “thinking” before replying, or text appearing word-by-word at different speeds, you’ll know exactly which phase is at work.
References:
https://docs.nvidia.com/nim/benchmarking/llm/latest/metrics.html
https://sankalp.bearblog.dev/how-prompt-caching-works/#llm-inference-basics