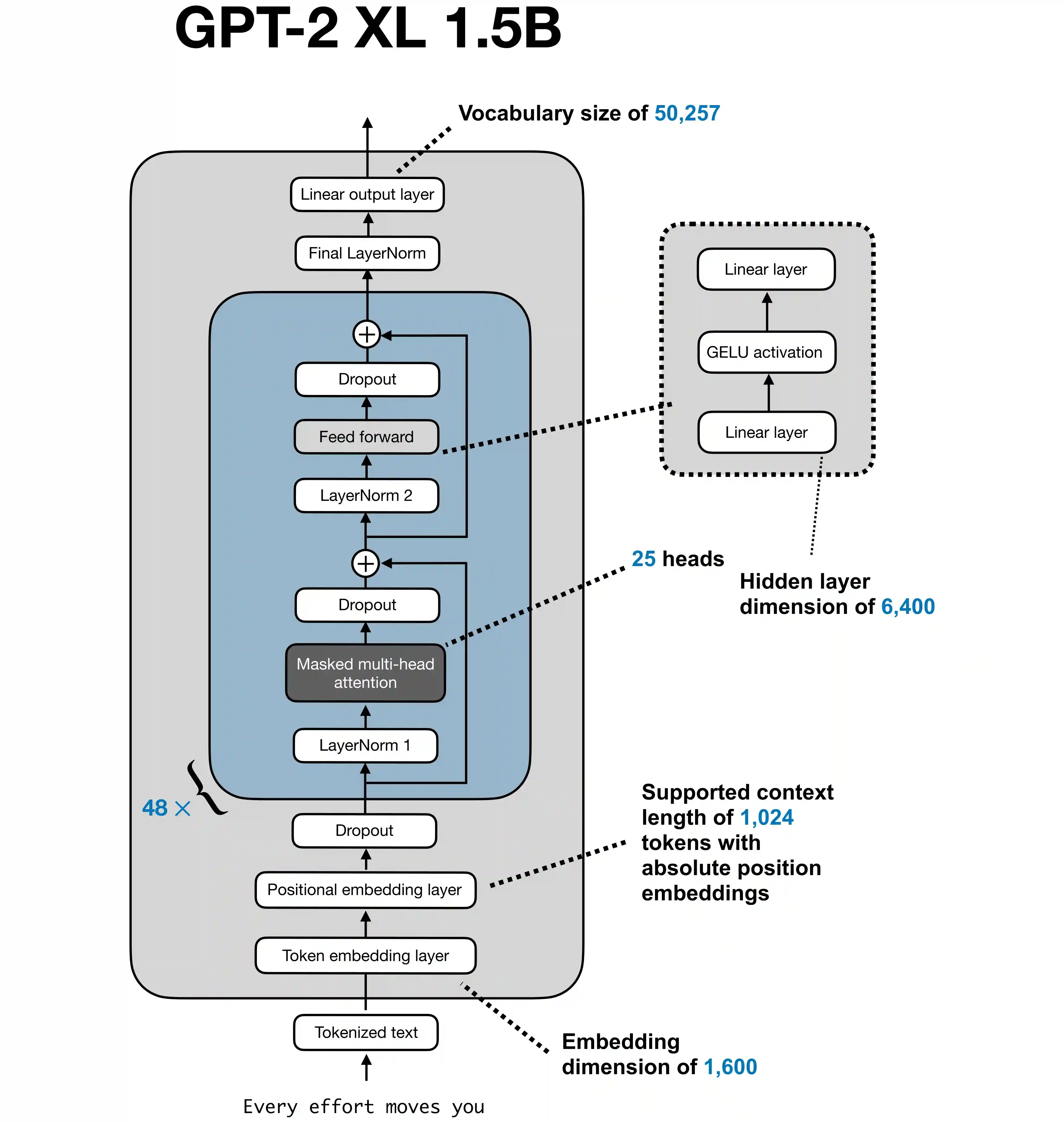
RoPE Explained: The Positional Encoding Trick Behind Modern Language Models
When people talk about transformers, they usually focus on attention, scale, or training data. But one smaller design choice has an outsized effect on model quality: How does the model know where each token appears in the sequence? That question matters because transformers do not understand order by default. Without positional information, a sequence starts to look more like an unordered set of tokens than a structured sentence, paragraph, or program. ...