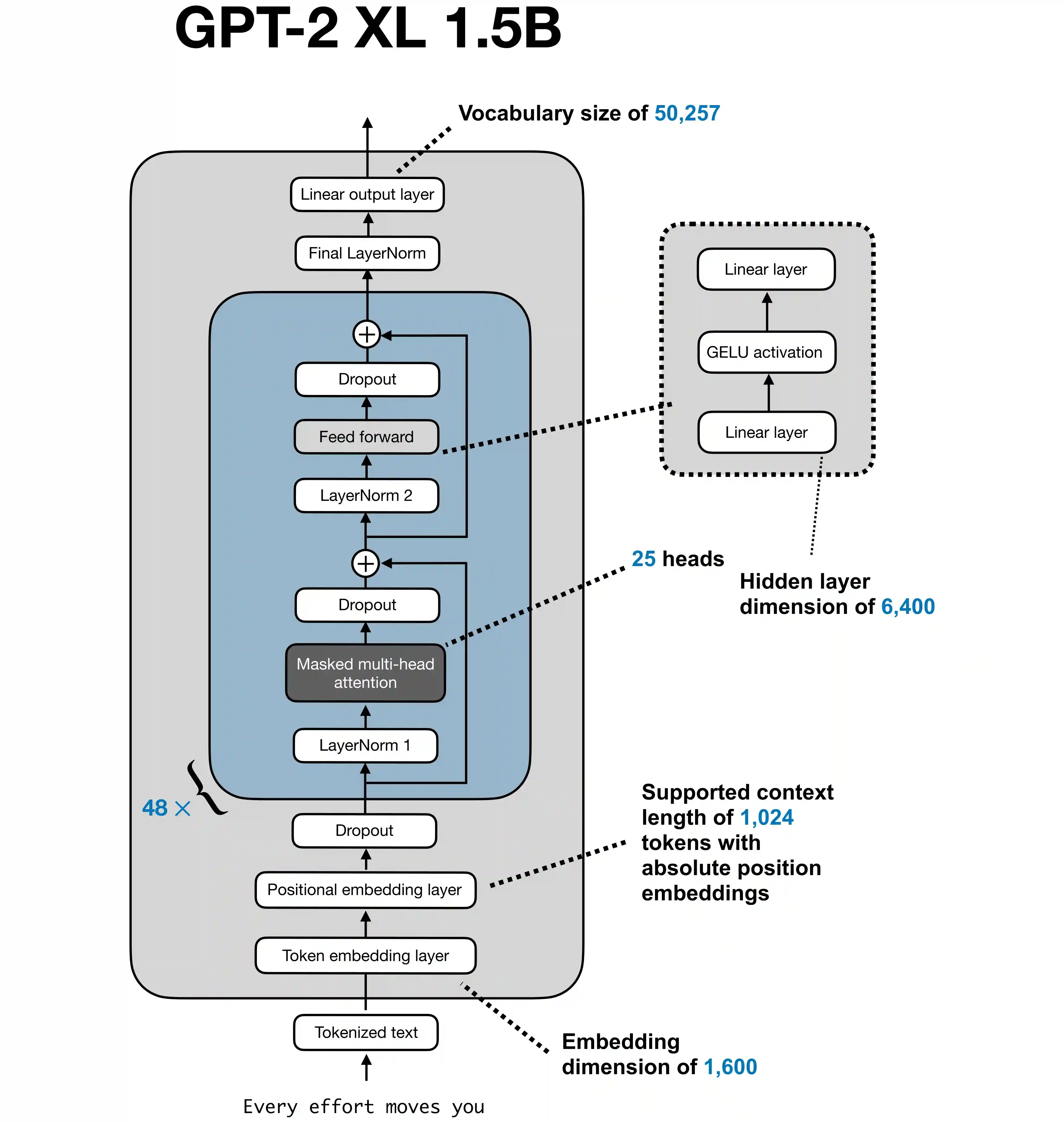
Forward Pass Explained: From a Single Neuron to Matrix Form
The forward pass is the part of a neural network that actually produces a prediction. You feed inputs into the model, the model applies a sequence of mathematical operations, and an output comes out the other side. That sounds trivial, but it is one of the most important ideas in deep learning because everything else depends on it: the loss compares the forward-pass output to the target backpropagation differentiates through the forward pass training is just repeating the forward pass and improving it The easiest way to understand the forward pass is to start with a single neuron and then scale it up into a full layer written in matrix form. ...