Frontier vision models have gotten really good at understanding images — but they’ve also had a consistent weakness:
They still often treat an image like a single static glance.
So if the answer depends on something tiny (a serial number, a distant street sign, a gauge reading, a small UI label), the model might miss it… and then it has to guess.
Google’s new capability called Agentic Vision, launched with Gemini 3 Flash, is a major step toward fixing that.
Instead of “one-shot vision,” it turns image understanding into an agentic loop, where the model can zoom, crop, rotate, annotate, and compute using code execution — and then use the results to answer with visual proof.
Let’s break it down properly, with use cases, demos, and code.
What is Agentic Vision?
Agentic Vision is a new capability in Gemini 3 Flash that combines:
✅ Visual reasoning (understanding images)
✅ Tool use via code execution (Python)
✅ A repeated reasoning loop (Think → Act → Observe)
✅ Output grounded in visual evidence, not guesswork
In simple terms:
Agentic Vision turns an image task into an investigation — not a prediction.
This matters because most vision tasks don’t fail because the model is “dumb” — they fail because the model didn’t look closely enough.
The core idea: Think → Act → Observe
Agentic Vision introduces an agent-like loop directly into the vision pipeline:
1) Think
The model analyzes:
- your question
- the image
- what information might be missing
- what steps are required to extract it
Example thought:
“I need to count pedals. I should zoom into the lower portion of the image and isolate the pedal board.”
2) Act
The model generates and executes Python code to manipulate the image.
This could include:
- cropping a region
- zooming in
- rotating an image
- drawing annotations
- counting objects
- reading tables and performing math
- plotting results with Matplotlib
3) Observe
The transformed image (cropped/zoomed/annotated output) is appended back into the model’s context.
Now the model can answer based on a clearer view of the evidence.
This loop can repeat multiple times until the model is confident.
Why this is a big deal (and not just hype)
Google claims that enabling code execution with Gemini 3 Flash brings a consistent ~5–10% quality boost across vision benchmarks.
That’s not a small improvement — especially for visual reasoning tasks that require:
- precision
- multi-step verification
- factual grounding
For real production apps, that can be the difference between:
- ✅ “works reliably”
and - ❌ “sometimes randomly wrong”
What can Agentic Vision do? Real-world behaviors
1) Zooming and inspecting fine details
This is the most immediately useful capability.
Instead of guessing from a blurry part of an image, the model actively zooms in.
Example use cases:
- reading a gauge value
- identifying a serial number
- inspecting small text in UI screenshots
- checking part numbers on chips/components
- document screenshots
A strong real-world example mentioned:
PlanCheckSolver.com, an AI building plan validation platform, reportedly improved accuracy by ~5% by enabling code execution to iteratively crop and inspect high-resolution building plan sections like roof edges and structural regions.
2) Image annotation (a “visual scratchpad”)
This is underrated but extremely powerful.
Instead of just replying:
“Looks like five fingers.”
Agentic Vision can:
- detect each finger
- draw boxes or labels
- produce a visual proof
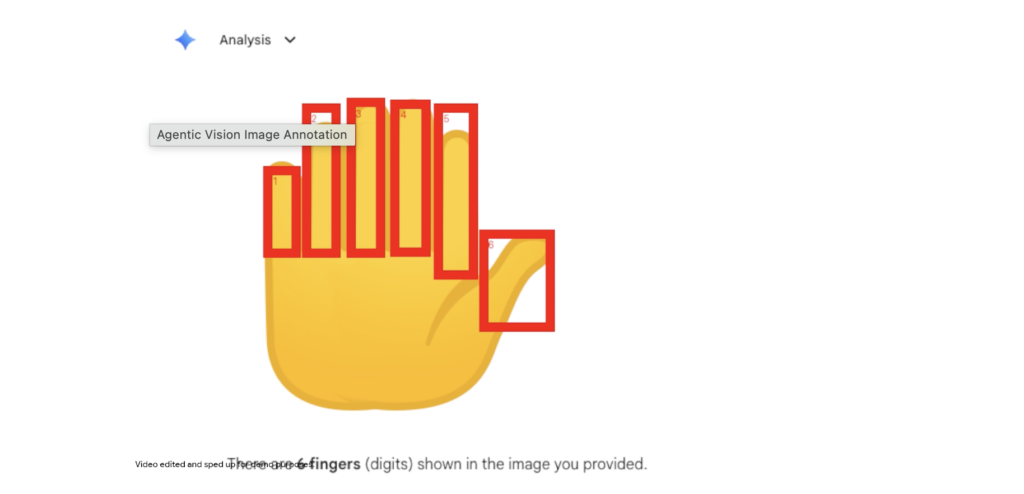
This prevents classic vision hallucinations.
A famous demo example is counting fingers on an emoji-style hand where many models default to “5 fingers” by assumption — but the image actually shows 6.
Agentic Vision solves that by marking each finger explicitly.
3) Visual math + plotting (tables and charts)
This is where “LLM guessing” fails hard.
Many models struggle with:
- reading dense tables from images
- doing multi-step arithmetic correctly
- comparing multiple values reliably
Agentic Vision helps by:
- extracting data visually
- offloading math to deterministic Python
- generating plots (e.g., Matplotlib) for verification
Instead of probabilistic arithmetic, you get a verifiable computation pipeline.
How to access Agentic Vision (Google AI Studio + API)
Agentic Vision is available via:
✅ Gemini API in Google AI Studio
✅ Vertex AI
✅ Rolling out into the Gemini app (via model dropdown “Thinking”)
To trigger Agentic Vision behavior, you typically enable:
Tools → Code Execution
That unlocks the “Act” part of the loop.
Python code walkthrough: enabling Agentic Vision
Below is the same style of code Google shared (and it’s simple enough to ship in a prototype immediately):
from google import genai
from google.genai import types
client = genai.Client()
image = types.Part.from_uri(
file_uri="https://goo.gle/instrument-img",
mime_type="image/jpeg",
)
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[image, "Zoom into the expression pedals and tell me how many pedals are there?"],
config=types.GenerateContentConfig(
tools=[types.Tool(code_execution=types.ToolCodeExecution)]
),
)
print(response.text)
What matters in this snippet?
The most important piece is here:
tools=[types.Tool(code_execution=types.ToolCodeExecution)]
That is what gives Gemini permission to:
- generate Python
- run it
- transform the image
- feed the output back into its reasoning loop
Without code execution, the model still has vision — but it loses the “agentic” behavior that makes it reliable for fine-grained tasks.
Where Agentic Vision is headed next
Google also hinted at what’s coming:
✅ More implicit behaviors
Right now, Gemini 3 Flash is already good at deciding when to zoom.
But other actions (like rotation, visual math, heavy transformations) may still require the user to nudge it via prompt.
The goal is for these actions to become fully automatic and implicit.
✅ More tools (web + reverse image search)
This is the natural next step:
Vision + Code execution is strong…
But vision + code + web grounding is even stronger.
That would allow:
- identifying objects/products
- verifying real-world information
- cross-checking visual claims
- reducing hallucinations even more
✅ Expansion to more model sizes
Currently, it’s focused on Flash.
Google has said they plan to expand beyond that.
For official blog check this : https://blog.google/innovation-and-ai/technology/developers-tools/agentic-vision-gemini-3-flash/